Wine Picker, Wine Recommender System based on similarity
Wine Picker demo website
The Team
Problem definition
As the popularity of wine increases, the wine market is also growing. However, due to the wide variety of wines, uncertain pricing, and the need to primarily purchase them from offline stores, there are high barriers for consumers to enter the market. To address this issue, we have developed a platform that recommends wines to users based on wine similarity and user preferences.
System design
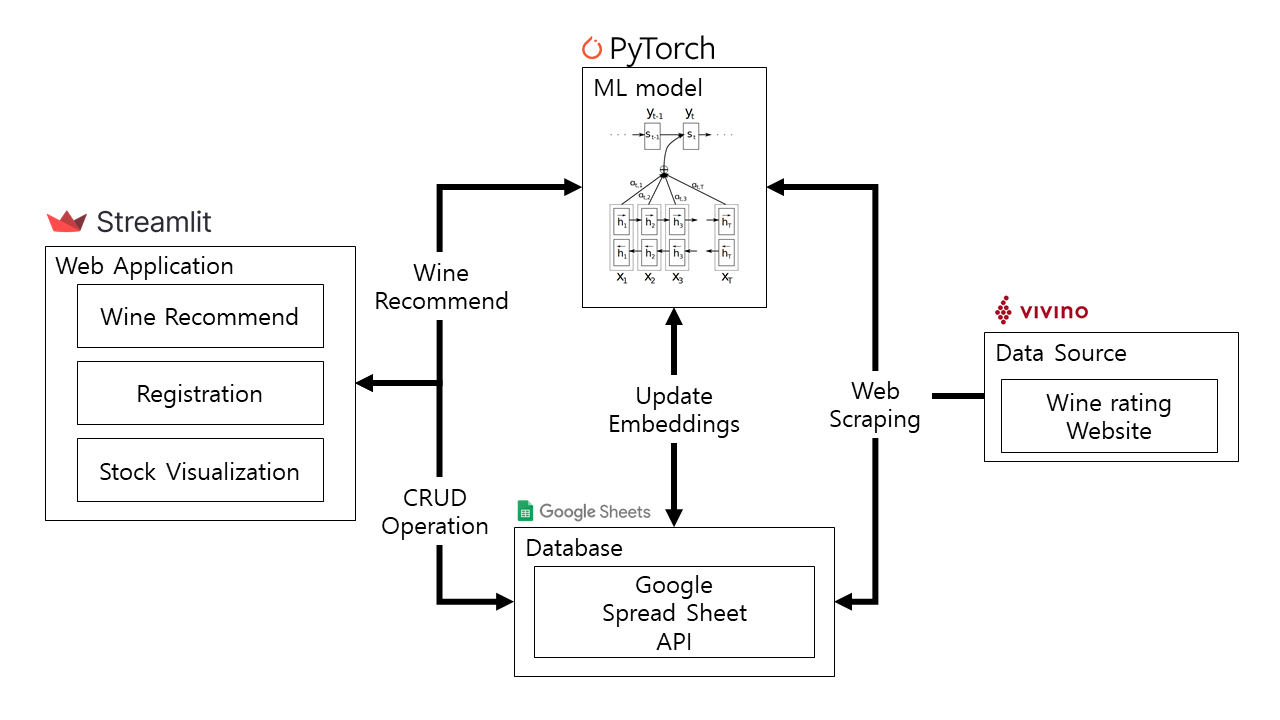
Figure 1: Block diagram of the proposed system
Our system consists of following 4 main components. Please refer to figure 1 for more details.
- A Machine Learning model, which recommends the best wine based on the individual user’s taste.
- A Streamlit Front-End, which provides the interface for end users to interact with our application
- A Data Source which is the third-party web site called Vivino, from which we scraped wine rating data.
- A Database, which are interacting with Web Application and ML model allowing them to perform CRUD operations and update embeddings, respectively.
Component 1: Machine Learning model
The goal of our machine learning model is to recommend the best wine to individuals based on their taste preferences among thousands of wines. We have used the PyTorch library in Python for easy facilitation of machine learning programming.
Component 2: Streamlit Front-End
Our system aims to be a wine recommendation platform and has been implemented in the form of a website to ensure accessibility across multiple devices. We utilized Streamlit as our framework, because it can be easily implemented by using Python code without requiring web programming knowledge. Additionally, Streamlit allows developers to visualize the result of data analysis. Furthermore, through Streamlit Cloud Community, we can easily deploy our application for free. Web Application provides registration, log in, wine and market recommendation and stock visualization while interacting ML model and database.
Component 3: Data Source
One of the challenges of this project was the lack of open datasets that reflect the preferences of actual consumers. Therefore, we utilized the Python Selenium library to scrape data from Vivino, a website where consumers can provide their wine ratings. The collected data includes features such as Bold, Tannic, Sweet, and Acidic, representing the aroma of the wine, its origin, grape breed, and price. In total, we collected a set of data consisting 1,488 entries.
Component 4: Database
The database is implemented using the Google Spread Sheet API. It operates on the cloud rather than local system, also allowing for remote hosting and enabling multiple users to work simultaneously. The initial data for the database was obtained by scraped data from Vivino, and tables were created based on this data. Subsequently, it interacts with the Streamlit Front-End to perform data CREATE, READ, UPDATE, and DELETE (CRUD) operations. Additionally, it passes embedding values to the ML model for wine recommendation and updates the calculated embeddings.
System Evaluation
To recommend wines, we need to solve the following problems:
- How to embed wine vectors into the wine embedding space.
- How to embed user vectors into the user embedding space.
- How to combine the wine and user vectors into the same space.
- How to recommend the best wine based on the user taste.
To solve the first problem, we utilized the word2vec approach even though the dataset is tabular. The features of wines (e.g., taste, aroma, wine type, grape, etc.) are considered trainable unit vectors, similar to word embedding vectors, but each feature’s value (e.g., how sweet a wine is) is reflected as the scaling. The wine embedding vectors are trained by masking random properties and predicting them (e.g., “how sweet a wine is”, “which wine type”, etc.).
Second, we created user vectors by combining wine vectors instead of creating new embedding vectors, because we do not have any user data, where it is impossible to build a user embedding space. Specifically, if a user inputs their taste preferences (e.g., bold: 0.7, tannic: 0.6, sweet: 0.3, acidic: 0.7), then we gather wines with similar features and randomly combine some wine embedding vectors to create a new vector, which becomes the user embedding vector. By using this approach, we can solve problems 1 and 2.
After building the user embedding vector, we update the user vector by dividing the wine rated by the user and the user vector internally. For example, if a user rates wine A as $\frac{4}{5}$, we divide the user vector and the wine vector by $\frac{1}{2}\times(1+\frac{1}{5}):\frac{1}{2}\times\frac{4}{5}$. Therefore, we can reasonably reflect the user’s taste preferences into the user vector without any additional information. Finally, we can solve the problems with a quite simple way in the given circumstance.
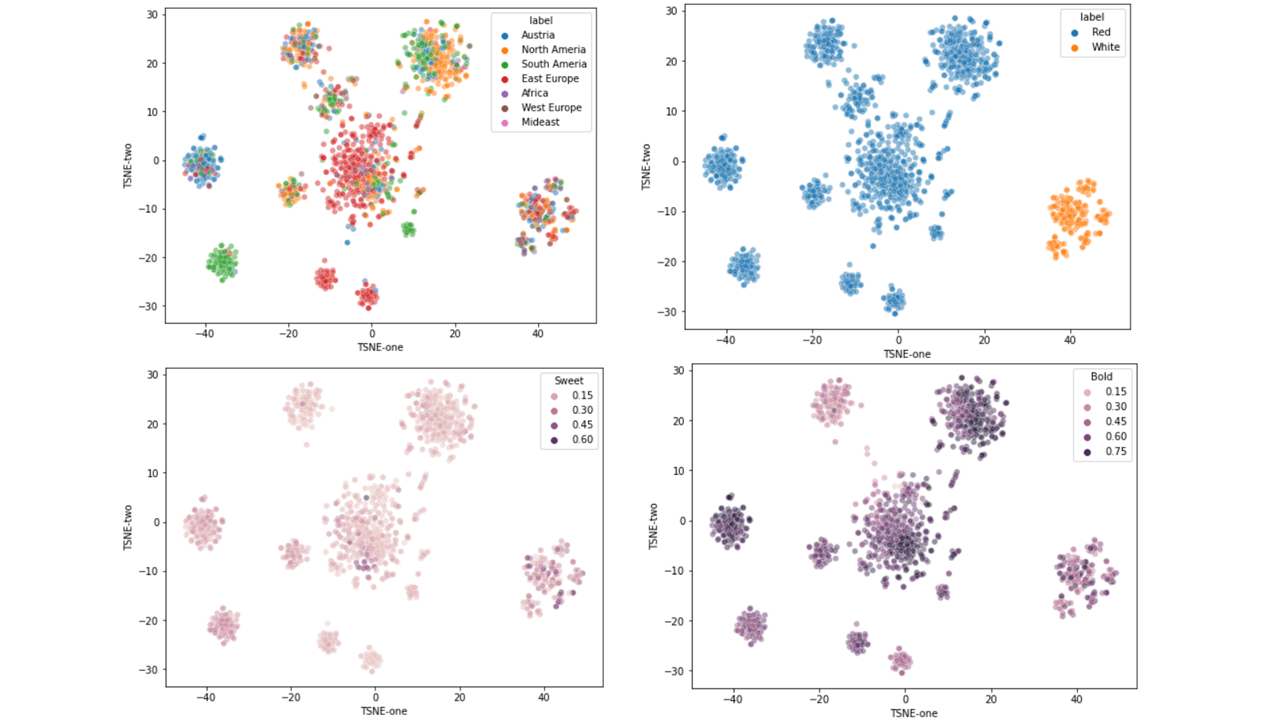
Figure 2: Visualization of wine embedding vectors
Application demonstration
- A unique wine recommendation service based on local store inventory.
- A personalized wine recommendation service based on user preferences and its embeddings.
- Various selection options available for choosing wines, including origin, grape breed, and taste.
- Provides users with wine choices based on inventory availability, assisting sellers with inventory management.
- Facilitates price comparison between selling price, online highest price, and lowest price by providing corresponding information.
Main

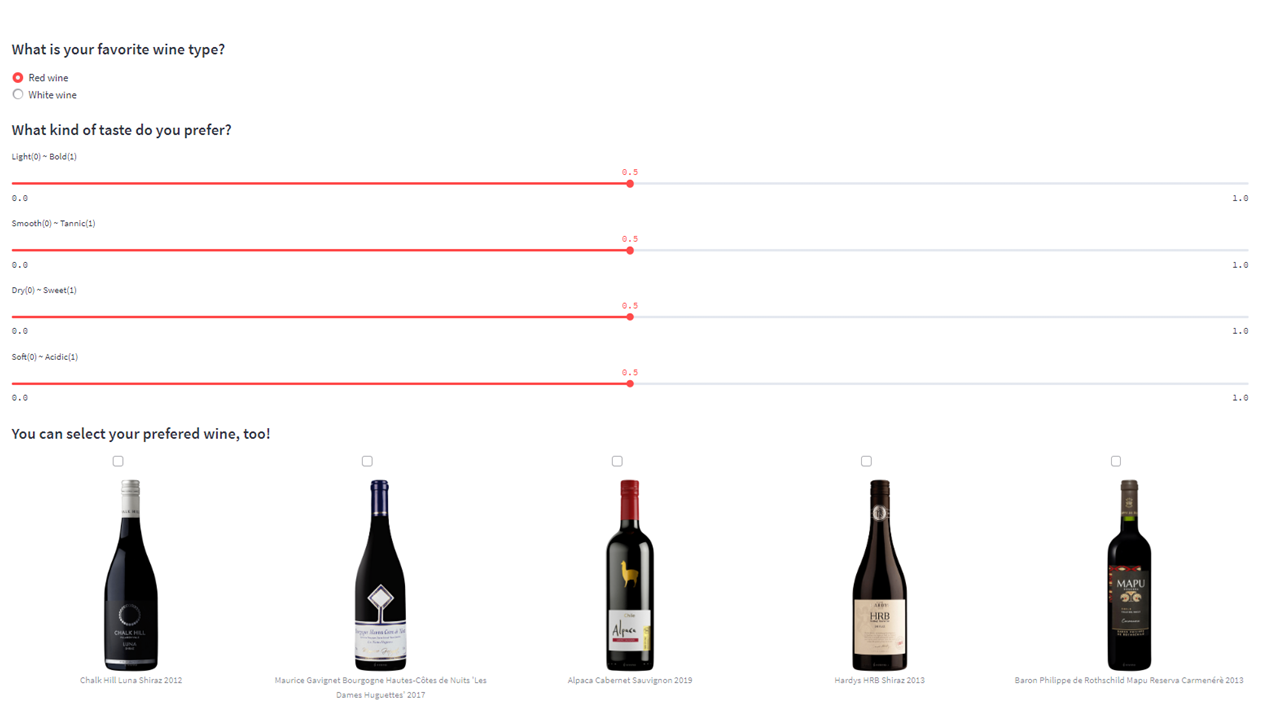
Figure 3, 4, 5: Application demonstration of the main page
Select the desired button between Login and Sign up.
In the Login section, the functionality is implemented by retrieving information from the database containing user data.
In the Sign up section, users can fill in their ID, password, and address information, and select their wine type and taste. After that, users can re-initialize the preferences through the same process. Furthermore, we have enabled users to select their preferred wines from existing options, allowing them to generate their embeddings that are similar to those wines.
Home
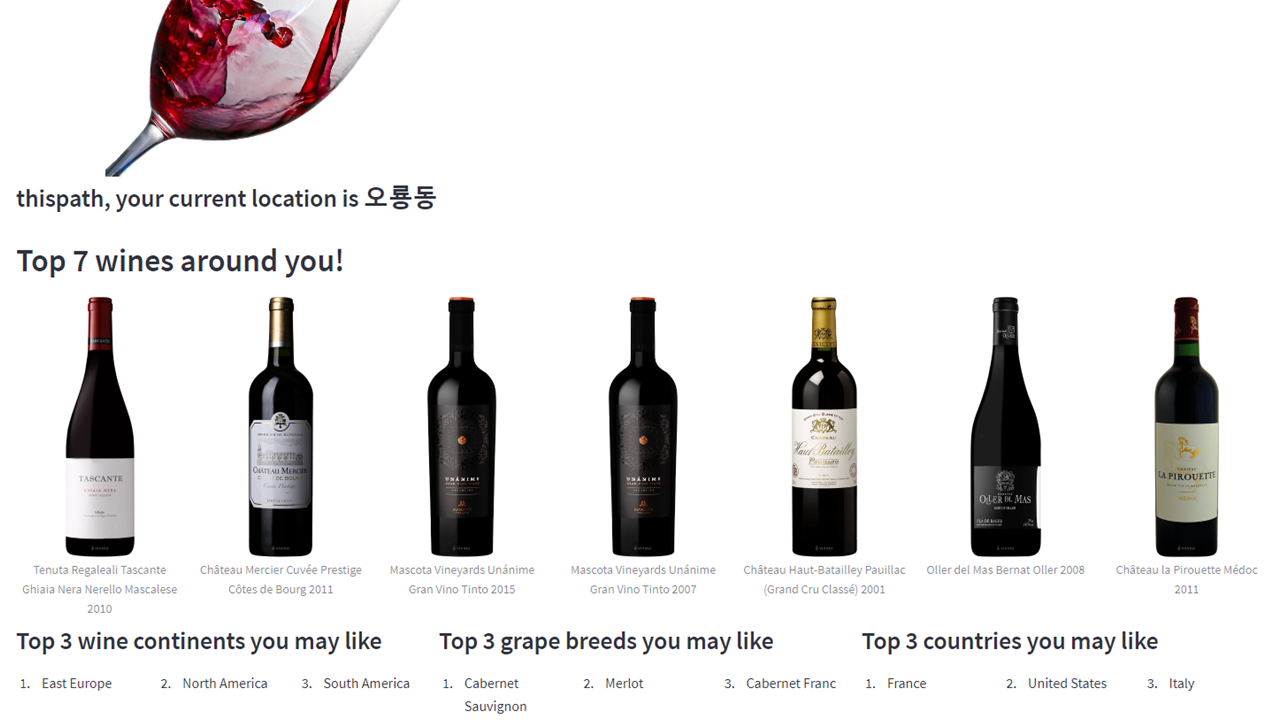
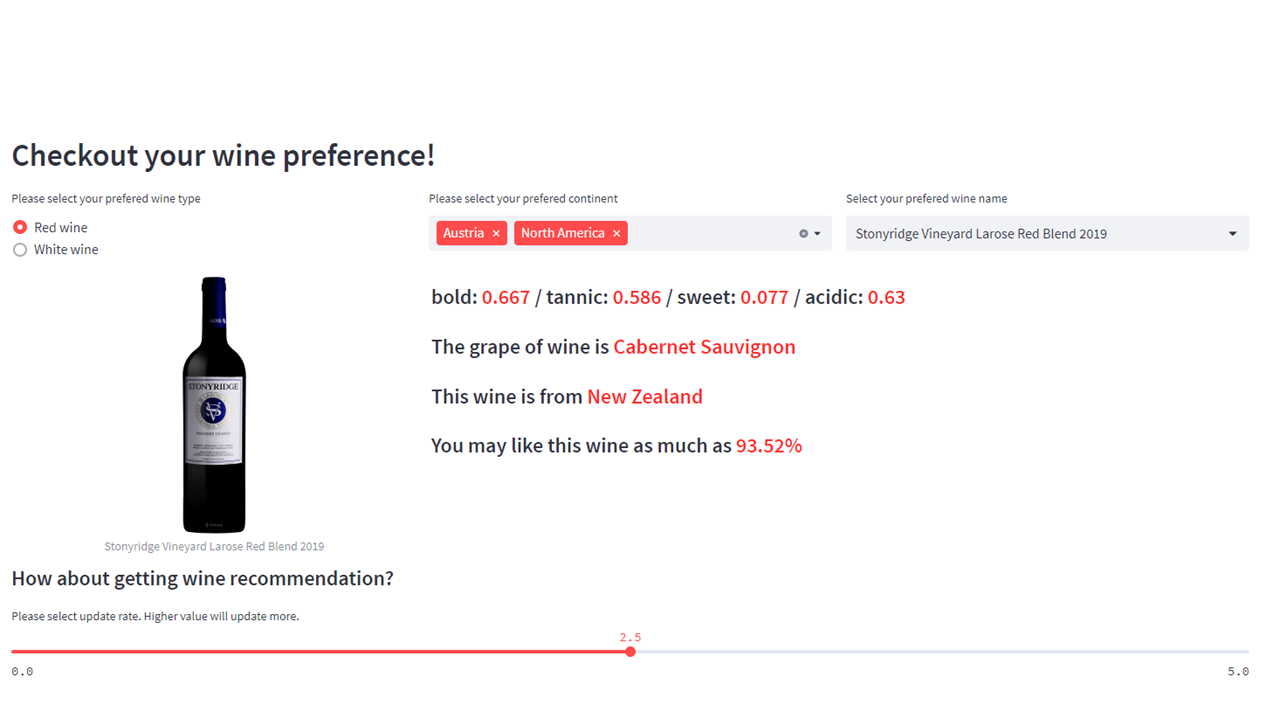
Figure 6, 7: Application demonstration of the home page
On the Home page, we present the top-k wines based on the user’s preferred wine information. Additionally, we provide additional information on continents, grape breeds, and countries to assist in wine selection. At the bottom, users can update information about their preferred wines. They can use a slider to determine the weight given to additional wines. When the Update button is clicked, newly recommended wines will be displayed.
Map
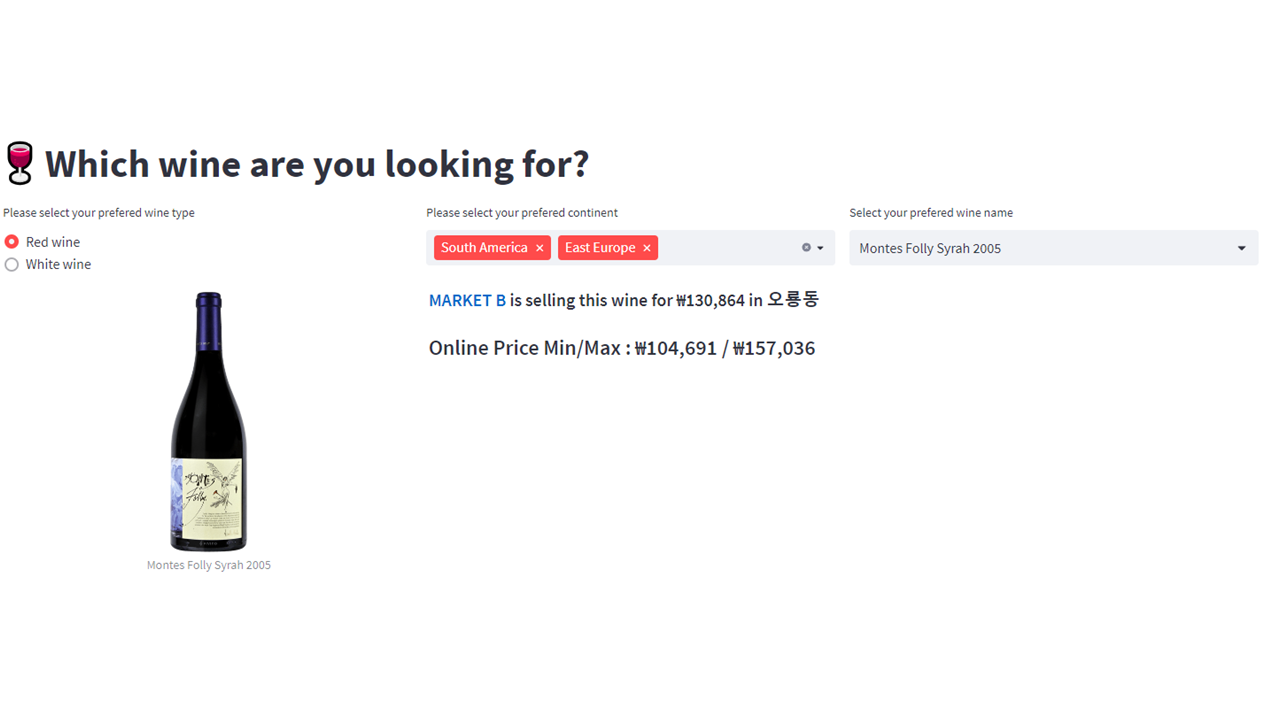
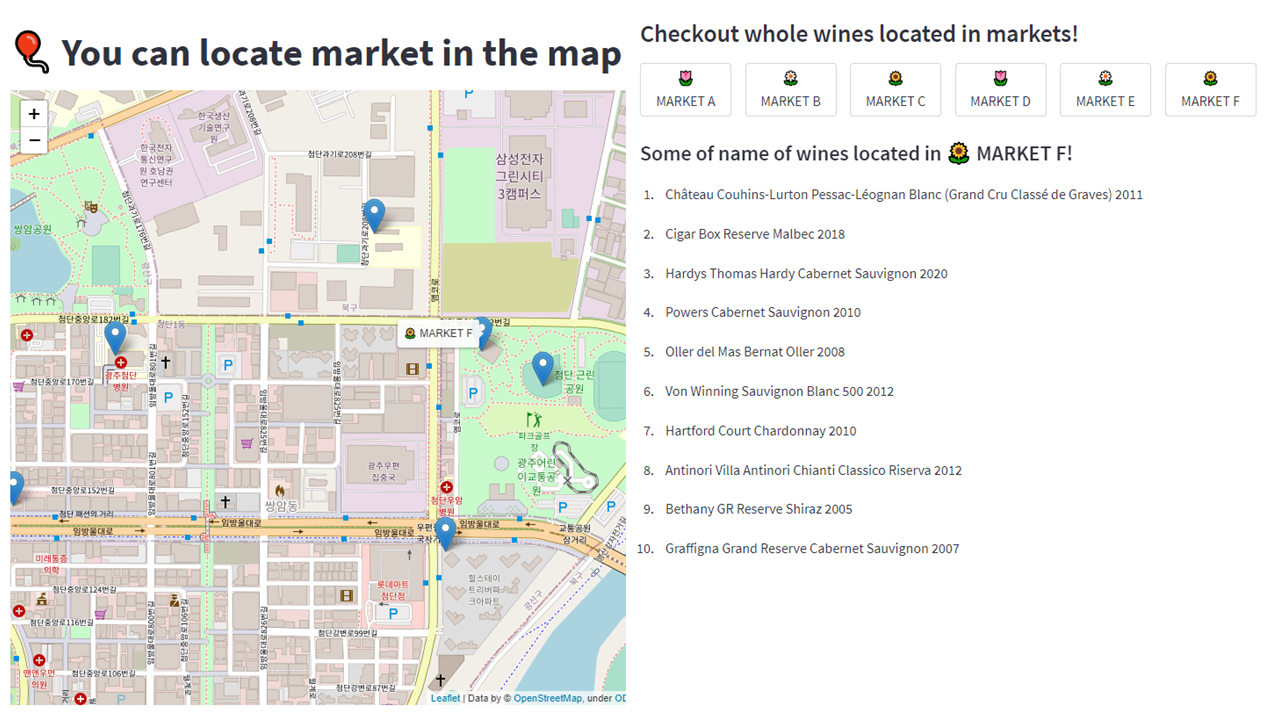
Figure 8, 9: Application demonstration of the map page
When searching for a desired wine, our platform displays the markets that have the wine in stock along with their respective prices. Users can also select nearby markets on the map, and clicking on the market buttons at the bottom provides a summarized view in a data frame format. Afterward, users are directed to a page that showcases the wine inventory of the selected market. On this page, users can view the wine’s image, type, continent, country, cost, as well as the online minimum and maximum prices.
Reflection
What Worked
-
The flavor profile of wine tends to vary based on the grape’s country of origin, and it was observed that when users explicitly expressed a preference for wines from a specific continent, they were recommended wines from the same continent. This indicates that personalized wine recommendations based on individual user embeddings were reliably implemented.
-
For collaboration among team members, GitHub is commonly used, and Streamlit deploys the product based on the GitHub repository. This advantage not only facilitates effective communication among team members but also allows real-time updates to be reflected in the functionality of the application.
What Didn’t Work So Well
- Database selection was one of the challenges. At the beginning of the project, we implemented the database through PostgreSQL, but we had to modify it due to the fact that it cannot be distributed online for free.
- Streamlit is Python-based, and it’s not easy to customize the design or functionality. Because of this, we were unable to customize the UI, and we were unable to handle the delay when loading images, which is likely due to the fact that it is not asynchronous despite using cache.
Future Improvements
- If we were to start a business, we could collaborate with actual stores to manage and recommend their inventory effectively.
- We could enhance speed and security by leveraging services like Cloudflare. Additionally, we could build a database using PostgreSQL, which we previously struggled with.
- We could visualize the embeddings of wines and users to provide users with a visual representation of similarity and similarity scores.
Broader Impacts
Possible intended uses
- Providing personalized wine recommendations to wine enthusiasts for an enjoyable wine exploration experience.
- Assisting sellers in inventory management to minimize stock loss.
Possible unintended uses
- Underage individuals using the service to engage in immature drinking behavior.
- Service promoting excessive alcohol consumption through wine purchase encouragement.
Design decisions for harm mitigation
- Age restrictions and user authentication during registration to restrict access for underage individuals.
- Providing users with information on appropriate alcohol consumption and promoting a healthy drinking culture.
- Offering guidance and warning messages emphasizing responsibility and the impact of wine consumption.
Through these design decisions, efforts have been made to minimize harm resulting from unintended use and ensure the safety and ethics of the service.